KI und synthetische Daten in der Kreislaufwirtschaft
Die Anwendung Künstlicher Intelligenz verspricht enorme Chancen für die Kreislaufwirtschaft, birgt aber auch ein hohes Risiko von KI-gestütztem Greenwashing. Entscheidend wird nicht die Technik selbst, sondern die Sicherung von Datenintegrität, Transparenz und unabhängiger Kontrolle sein. Ein Beitrag von Nicole Stein.
Die Bezeichnung QE-Programm (Quantitative Easing) ist nicht die offizielle Bezeichnung des Programms der EZB, sondern bezeichnet lediglich eine geldpolitische Methode, bei der die Zentralbank Schuldtitel kauft, um das Niveau der Marktzinsen nach unten zu drücken. Das QE-Programm heißt im offiziellen EZB-Sprachgebrauch Programm zum Ankauf von Vermögenswerten (Asset Purchase Programme, APP) und wurde Anfang 2015 beschlossen. Das APP bestand zunächst aus drei Einzelprogrammen zum Ankauf
gedeckter Schuldverschreibungen (CBPP 3, Start Oktober 2014),
forderungsbesicherter Wertpapiere (ABSPP, Start November 2014) und
von Wertpapieren des öffentlichen Sektors (PSPP, Start März 2015).
Im Juni 2016 kam das Programm zum Ankauf von Wertpapieren des Unternehmenssektors (CSPP) hinzu.
Eine genauere Beschreibung der einzelnen Programme finden Sie am Ende dieses Beitrags.
Die EZB hat für die einzelnen Programme keine konkreten Kaufvolumina, sondern lediglich monatliche Zielmarken für das gesamte APP festgelegt.
März 2015 bis März 2016: 60 Milliarden Euro
April 2016 bis März 2017: 80 Milliarden Euro
April 2017 bis Dezember 2017: 60 Milliarden Euro
Januar 2018 bis September 2018: 30 Milliarden Euro
Was kauft die EZB genau?
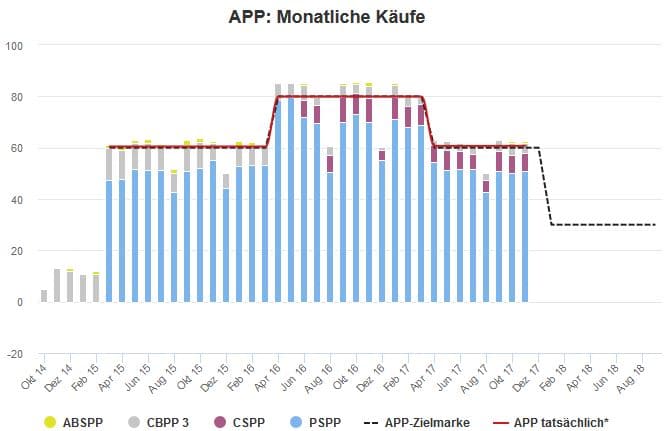
Der Blick auf die pro Monat aufgekauften Wertpapiere zeigt, dass die EZB durchaus die Zusammensetzung ihrer Käufe variiert hat und im Rahmen der einzelnen Programme unterschiedlich aktiv war. Auch lag das monatliche Kaufvolumen nicht immer präzise bei den angekündigten 60 bzw. 80 Milliarden Euro – allerdings hat die EZB während der jeweiligen Phasen im Durchschnitt doch ziemlich exakt das angekündigte Volumen gekauft.
*APP tatsächlich: Diese Linie zeigt, wie viel die EZB während der bisherigen drei Phasen des APP (Zielwert März 2015 bis März 2016: 60 Milliarden Euro, Zielwert April 2016 bis März 2017: 80 Milliarden Euro, Zielwert April 2017 bis Dezember 2017: 60 Milliarden Euro) durchschnittlich pro Monat gekauft hat. Quellen: EZB, eigene Berechnungen
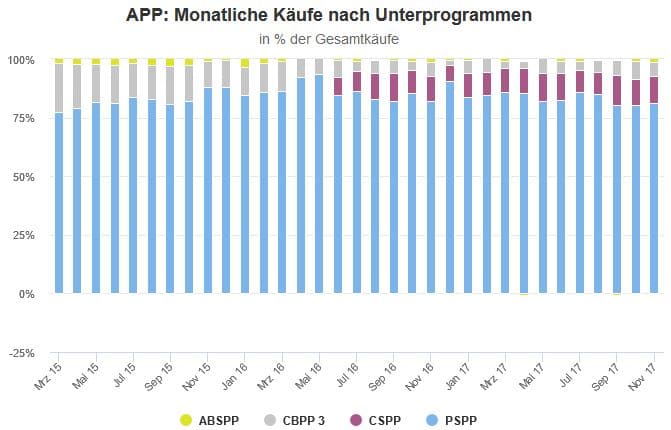
Die unterschiedliche Gewichtung der Unterprogramme wird im folgenden Chart noch etwas deutlicher. Dieser zeigt, wie hoch der Anteil der jeweiligen Programme während der einzelnen Monate seit Start des APP im März 2015 war. Daraus wird ersichtlich, dass die EZB den Anteil der gekauften Staatsanleihen zuletzt wieder etwas reduziert hat (von in der Spitze über 90% auf zuletzt etwa 80%).
Quellen: EZB, eigene Berechnungen
Worauf es zu achten gilt: Konkrete Umsetzung und Reinvestitionen fälliger Anleihen
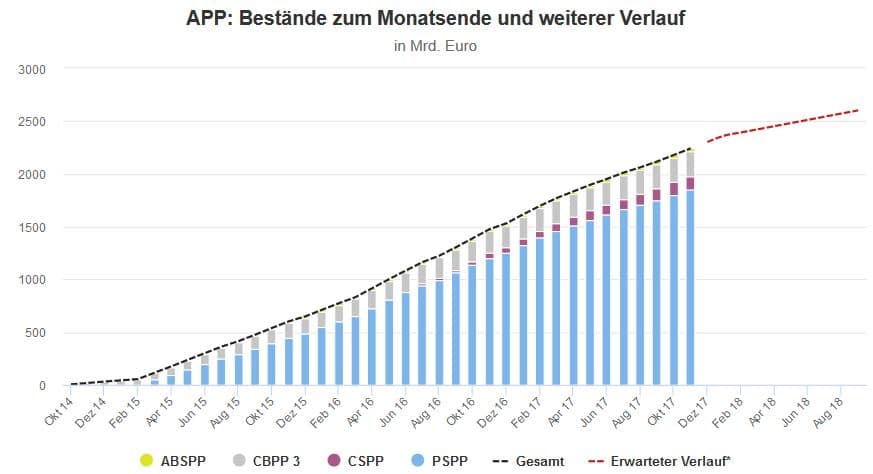
In den kommenden Monaten gilt es also vor allem zu beobachten, wie die EZB die angekündigte Reduzierung ihres Aufkaufvolumens konkret umsetzt, weil sich dies auf die betroffenen Marktsegmente unterschiedlich auswirken wird. So hat die EZB wie oben gezeigt seit Start ihrer Aufkaufprogramme demonstriert, dass sie in der Lage und gewillt ist, die angekündigten Kaufvolumina auch tatsächlich umzusetzen. Das heißt, dass die gesamten APP-Bestände in ihrer Bilanz ungefähr dem im folgenden Chart skizzierten Verlauf (rote gestrichelte Linie) folgen und Ende September 2018 ein Gesamtvolumen von ca. 2,6 Billionen Euro erreichen dürften – die Frage ist eben lediglich, durch welche Wertpapiere die große weiße Lücke im Chart konkret gefüllt wird.
Anmerkung: Die Bestände werden immer am Ende eines Quartals um Amortisierungen bereinigt. Das bedeutet, dass der Wert von unter ihrem Nominalwert gekauften Anleihen nach oben korrigiert werden, wenn sie näher an ihren Fälligkeitstermin kommen. Für über Nominalwert gekaufte Anleihen gilt entsprechend eine Abwärtskorrektur. *Erwarteter Verlauf auf Basis der EZB-Ankündigung, ab Januar 2018 im Rahmen des APP monatlich Wertpapiere im Wert von 30 Milliarden Euro erwerben zu wollen. Die Reinvestionsvolumina sind nicht dabei nicht berücksichtigt. Quellen: EZB, eigene Schätzungen
Es muss auch berücksichtigt werden, dass das APP noch lange über sein eigentliches Ende hinaus Wirkung entfalten wird. So hat die EZB bereits im Dezember 2015 angekündigt, die Einkünfte aus bis zur Fälligkeit gehaltenen Anleihen wieder zu reinvestieren und dieses Versprechen auf der Oktober-Ratssitzung noch einmal erneuert und präzisiert. Sollte also beispielsweise eine deutsche Staatsanleihe 2019 fällig und die EZB vom deutschen Staat ausbezahlt werden, wird sie – Stand heute – dieses Geld für den erneuten Erwerb einer (deutschen) Staatsanleihe nutzen. Ihre Bestände an Staatsanleihen werden sich somit nicht zwangsläufig verringern und ihre Präsenz auf den Märkten auch nicht sehr viel kleiner werden – sie schafft nur kein neues Geld, um Staatsanleihen zu erwerben.
QE-Käufe nach Ländern
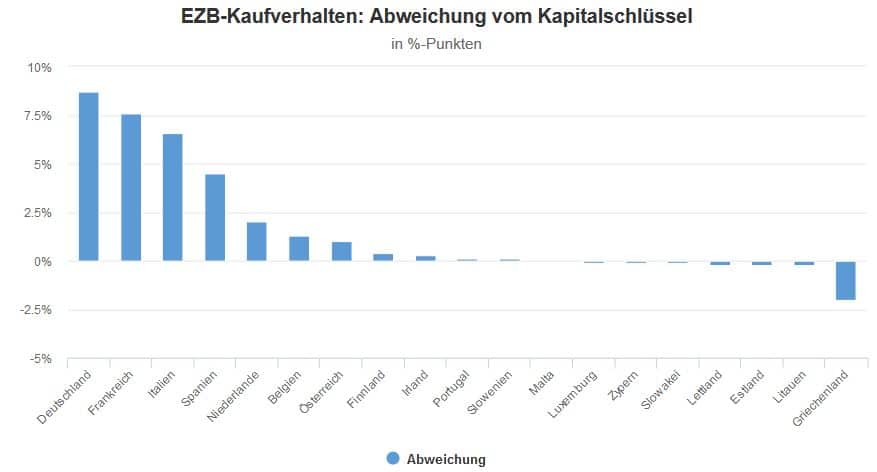
Die EZB hat beim Start des PSPP (also des Staatsanleihen-Programms) angekündigt, dass sich das Kaufvolumen am Kapitalschlüssel der beteiligten Länder orientieren soll. Jedoch ist die EZB von diesem Ziel deutlich abgewichen: Sie hat mehr Staatsanleihen der großen Eurostaaten gekauft, als dies eigentlich nach dem Kapitalschlüssel angemessen gewesen wäre. So machen beispielsweise deutsche Staatsanleihen mittlerweile knapp 27% des aufgekauften Staatsanleihen-Portfolios aus, obwohl der deutsche Kapitalschlüssel nur bei knapp 18% liegt.
Quellen: EZB, eigene Berechnungen
Diese “Bevorzugung” der großen Staaten könnte unter anderem darauf zurückzuführen sein, dass es bei den kleineren Ländern schlicht nicht genug Anleihen gibt, damit die EZB ihr angepeiltes Kaufvolumen erreichen kann. Es wird sich zeigen, ob die EZB somit ihr Kaufverhalten ändern wird, wenn sie nur noch eine kleinere Summe an Staatsanleihen aufkaufen muss.
Bilanzsumme
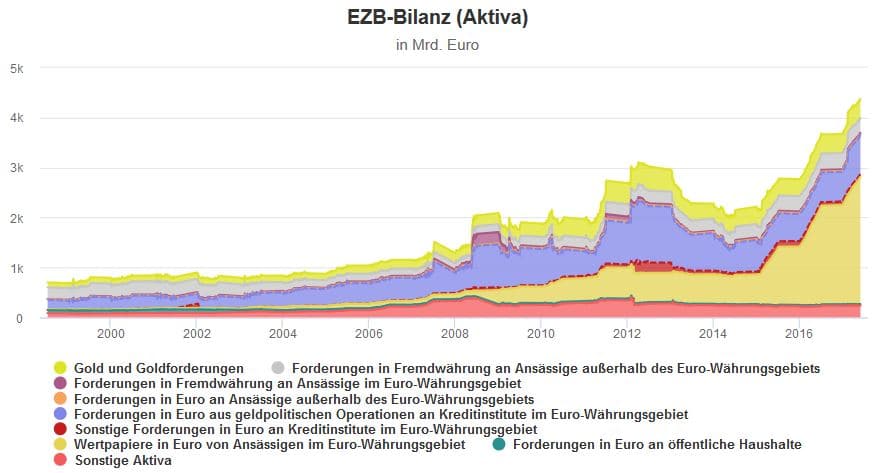
Die im Rahmen des QE-Programms getätigten Käufe machen inzwischen fast die Hälfte der insgesamt knapp 4,4 Billionen Euro großen EZB-Bilanz aus. Wenn die EZB die Summe der monatlichen Anleihekäufe ab Januar senkt, ist in der kurzen Frist zu erwarten ist, dass sich die EZB-Bilanz zunächst etwas langsamer ausweiten wird. Um die tatsächliche expansive Wirkung der Geldpolitik zu beurteilen ist es aber auch notwendig zu beobachten, wie sich die übrigen Posten der Bilanz verändern, was aus heutiger Sicht aber nicht abschätzbar ist.
Quelle: EZB
Glossar: Die Programme im Detail
Das erste Programm zum Ankauf gedeckter Schuldverschreibungen (Covered Bond Purchase Programme, CBPP) wurde bereits 2009 von der EZB beschlossen, um nach der Finanzkrise den Markt für diese Papiere (z. B. Pfandbriefe) zu stabilisieren und Refinanzierungsproblemen der Banken entgegenzuwirken. Innerhalb eines Jahres wurden Wertpapiere im Gesamtvolumen von 60 Milliarden Euro angekauft. Ein zweites CBPP mit folgte dann von November 2011 bis Oktober 2012. Das aktuell laufende dritte CBPP wurde im Oktober 2014 verabschiedet.
Das Programm zum Ankauf forderungsbesicherter Wertpapiere (Asset Backed Securities Purchase Programme, ABSPP) wurde im September 2014 in Verbindung mit dem Programm zum Ankauf gedeckter Schuldverschreibungen (CBPP 3) beschlossen. Dabei werden ABS-Papiere am Primär- und Sekundärmarkt aufgekauft.
Im Rahmen des Programms zum Ankauf von Wertpapieren des öffentlichen Sektors (Public Sector Purchase Programme, PSPP) werden seit März 2015 Wertpapiere des öffentlichen Sektors wie Staatsanleihen sowie Schuldtitel europäischer Institutionen und Agenturen gekauft. Für die Ankäufe im Rahmen des PSPP gibt es detaillierte Regeln. So dürfen Staatsanleihen beispielsweise wegen des Verbots der monetären Staatsfinanzierung nur am Sekundärmarkt erworben werden. Es dürfen nur Papiere mit einer Laufzeit von mehr als einem Jahr aufgekauft werden. Zudem will die EZB nicht mehr als 33% aller auf den Sekundärmärkten befindlichen Papiere aufkaufen.
Mit dem Programm zum Ankauf von Wertpapieren des Unternehmenssektors (Corporate Sector Purchase Programme, CSPP) werden seit Juni 2016 auch Anleihen von Unternehmen in der Eurozone erworben. Ausgeschlossen sind Kreditinstitute und Unternehmen, deren Anleihen von den Ratingagenturen nicht mindestens als „Investment Grade“ bewertet werden. Die Anleihen müssen Laufzeiten zwischen sechs Monaten und 30 Jahren haben und können sowohl am Primärmarkt als auch am Sekundärmarkt gekauft werden.
Sie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Sie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.