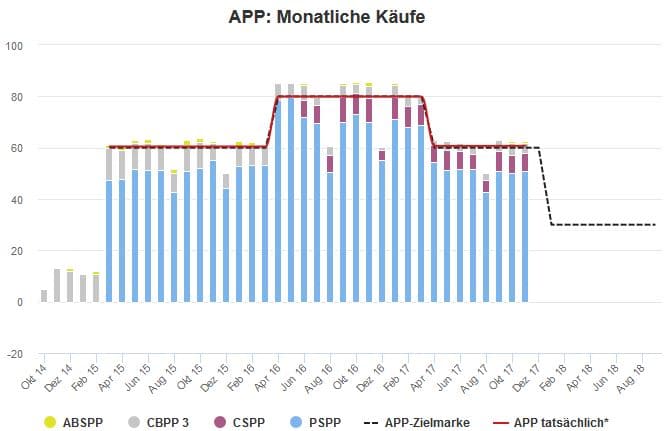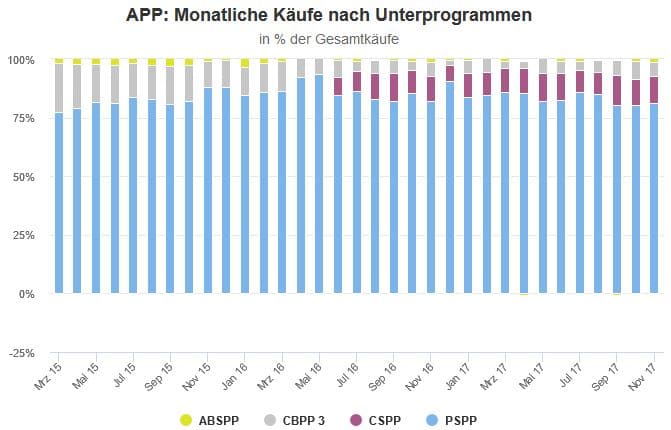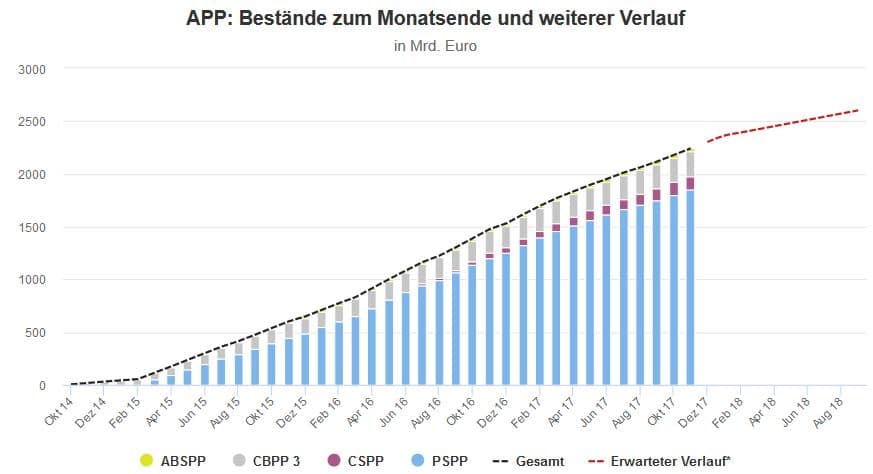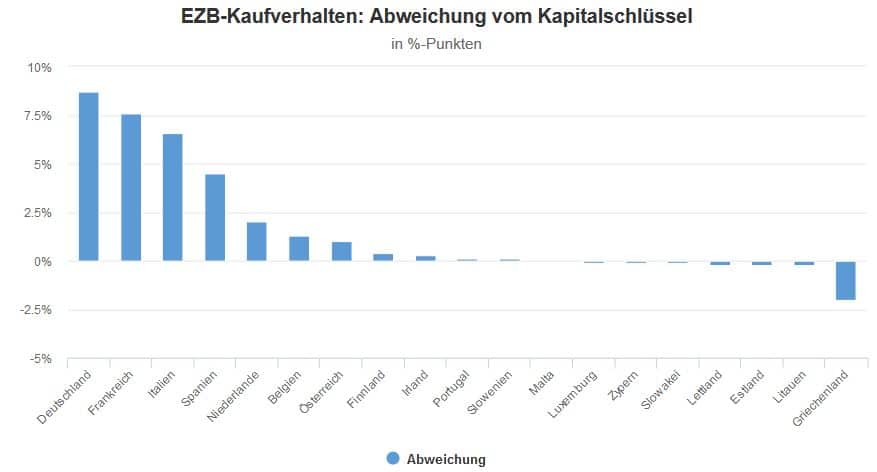






















Sollten wir andere Wege finden, um Daten zur Ungleichheit zu erheben und die Art verändern, wie wir sie messen? Tatsächlich erheben wir die Daten und verwenden die Methodologie ja nicht unabhängig von unseren Interessen und unserem Weltbild.
Um das verständlich zu machen, lassen Sie mich drei Wege erklären, die historisch die Erhebung von Daten zur Einkommensverteilung charakterisiert haben. Diese legten ihren Schwerpunkt auf
- die horizontale Ungleichheit,
- die Mittelschicht und die Verteilung von Einkommen mit Ausnahme der Spitzengruppe
- und die Spitzengruppe der Einkommensverteilung.
Horizontale Ungleichheit
Der erste Ansatz (horizontale Ungleichheit) besteht aus dem Interesse an den Durchschnittseinkommen von verschiedenen Gruppen, die daraufhin überprüft werden, wie sie sich unterscheiden und wie sie sich über die Zeit entwickeln. Die Verteilungen um diesen Durchschnitt herum ist von zweitrangiger Bedeutung: sie werden zwar erhoben, aber ihnen kommt keine besondere Aufmerksamkeit zu.
Dieser erste Ansatz ist in den 20er Jahren in der Sowjetunion entstanden, wo in regelmäßigen Abständen vom Staat Haushaltsbefragungen durchgeführt wurden. Den Sowjets ging es weniger um die Einkommensverteilung, sondern vielmehr darum, wie ein „typischer“, „durchschnittlicher“ Arbeiter im Vergleich mit einem „durchschnittlichen“ Bauern und später mit einem „durchschnittlichen“ Kolchosbauern abschnitt.
Der Fokus dieser Untersuchungen lag also auf den „Durchschnitten“: Arbeiter mit durchschnittlichen Fähigkeiten, mit einem Partner (Ehefrau) mit ebenfalls durchschnittlichen („normalen“, „gewöhnlichen“) Fähigkeiten, und Kindern im „typischen“ Alter etc.
Offensichtlich wurden diese Daten nicht nur für solche Durchschnittshaushalte erhoben, sondern auch für diejenigen, die ein bisschen weniger gewöhnlich waren. Allerdings interessierten sich die Befragungen nicht für die Extreme: weder die Armen, noch die ungewöhnlich Reichen wurden einbezogen.
Das hat in allen sozialistischen Ländern dazu geführt, dass es in den 60er Jahren einen Überfluss von (veröffentlichten) Daten gab, die die Unterschiede zwischen Durchschnittseinkommen von Arbeitern gegenüber Bauern oder von Beschäftigten gegenüber Rentnern maßen. Aber dieser Ansatz hat beide Enden der Verteilung (die Spitze und den unteren Rand) nicht ausreichend abgebildet und die Verteilung selbst verkürzt. Der Ansatz war weder für die Abbildung von Ungleichheit, noch für Armutsstatistiken wirklich geeignet.
Bevor Sie aber zu dem Schluss kommen, wie begrenzt dieser Ansatz war, denken Sie noch einmal nach: Denn es ist genau der gleiche Ansatz, der heute von denen verwendet wird, die sich (fast) nur um die Gender-, Rassen- oder andere Formen von „Typus gegen Typus“-Ungleichheit kümmern. Sie konzentrieren sich darauf, ob Frauen im Durchschnitt geringer bezahlt werden als Männer. Dieses Anliegen ist natürlich – genau wie der altmodische sowjetische Ansatz, wie Arbeiter gegenüber Bauern abschneiden – absolut legitim ist, berücksichtigt aber nicht die gesamte Verteilungsskala.
Ich habe diesen Ansatz in meinem jüngsten Buch kritisiert, indem ich aufzeige, dass wir, wenn wir die Durchschnitte gleichsetzen, es nicht schaffen, die Ungleichheit zwischen Frauen und zwischen Männern abzubilden: Die Verteilungen können sich stark unterscheiden, obwohl sie im Durchschnitt gleich sind. Dementsprechend kann es auch nur ein Anfang sein, die Durchschnitte anzugleichen.
Einkommensverteilung: Fokus auf die Mittelschicht
Der zweite Ansatz ist durch die Erhebung von Daten zur Einkommensverteilung charakterisiert. Viele Länder begannen mit der Erhebung von standardisierten Daten in den 50er und 60er Jahren. Wir beschäftigten uns dabei mit der gesamten Verteilung: mit den Armen, den weniger Armen, der Mittelschicht, der gehobenen Mittelschicht usw. Aber größtenteils liegt der Fokus auf den „dominanten“ großen Gruppen, also den Mittelschichten und nicht der Spitze der Einkommensverteilung. Dafür gibt es zwei Gründe:
Der erste liegt in der amtlichen Geheimhaltung. Seitdem viele westliche Länder begannen, den öffentlichen Zugang zu Mikrodaten zu gewähren, waren viele Statistikbehörden besorgt, dass sehr reiche Menschen, von denen es nur einige wenige gab, identifiziert werden könnten, wenn Forscher Zugang zu ihrem Alter, ihrer Bildung, der Zahl ihrer Kinder und ihrem Wohnort hätten. Somit wäre die von den Untersuchungen grundsätzlich garantierte Anonymität (auf die die Befragungen angewiesen waren, um die Teilnahme der Menschen zu sichern) ernsthaft kompromittiert worden. Dementsprechend wurden die Reichen unterdurchschnittlich berücksichtigt.
Der zweite Grund ist, dass extrem reiche Menschen ziemlich selten sind und wenn sie (einer oder zwei von ihnen) tatsächlich in einem Jahr bei einer Befragung berücksichtigt wurden (zur Erinnerung: Befragungen sind Stichproben), könnte dies die Ungleichheitsstatistiken ungewöhnlich erhöhen und die Ergebnisse stark von den historischen Daten abweichen lassen. Wenn ein Forscher die Ungleichheit untersucht, würde es danach aussehen, dass die Ungleichheit aus irgendeinem fundamentalen Grund stark gestiegen ist, obwohl es nur dazu kam, weil nur ein paar reiche Leute mehr als sonst in der Befragung berücksichtigt wurden.
Daher haben sich einige Statistikbehörden dafür entschieden, die Spitze der Einkommensverteilung durch das sogenannte „top-coding“ zu zensieren, das ein Maximum für das Einkommen festlegt, das entweder für eine Kategorie oder insgesamt ausgewiesen wird. Wenn Sie beispielsweise mitgeteilt haben, dass ihre Kapitaleinkünfte fünf Millionen US-Dollar betrugen, und der „top code“ für diese Kategorie aber eine Million war, würde die Befragung Ihr Einkommen als eine Million registrieren.
Konzentration auf die obersten 1%
Hier kommen wir zu dem dritten Ansatz. Seitdem die reichen Volkswirtschaften ungleicher geworden sind und sich die Lücke zwischen der Spitze der Einkommensverteilung und dem Rest vergrößert hat, hat sich sowohl das öffentliche Interesse als auch das der Forschung auf die Spitze verlagert. Diese Entwicklung korrespondiert mit der Entwicklung der gesellschaftlichen Interessen: Von der Frage, wie ein typischer Arbeiter im Vergleich zu einem typischen Bauern abschneidet, über die Frage, wie ungleich eine Gesellschaft und wie groß die Mittelschicht ist, hin zu der Frage, wie reich die obersten 1% sind.
Die Verwendung von Steuerdaten, die durch Thomas Pikettys Nutzung französischer Daten populär geworden ist, trägt diesem Interesse Rechnung (oder hat vielleicht selbst dazu beigetragen, dieses Interesse zu schaffen). Sogar die verwendeten statistischen Indikatoren haben sich verändert: Anstatt eine allgemeine Verteilungsstatistik wie den Gini-Koeffizienten zu nutzen, lag der Fokus auf den Anteilen der Spitzenverdiener.
Die Steuerdaten liefern tatsächlich ein besseres Bild der Spitzeneinkommen als die Haushaltsbefragungen. Nichtsdestotrotz arbeitet etwa die US-amerikanische Bundessteuerbehörde IRS in die Datensätze, die sie der Forschung zur Verfügung stellt, immer noch eine gewisse beabsichtigte „Unschärfe“ an der Spitze ein. Aber wir können dennoch auf wesentlich bessere Daten zum Vorsteuereinkommen der obersten 1% zurückgreifen, als es mit den Haushaltsbefragungen möglich war (einen kürzlich erschienen Vergleich zwischen Befragungen und Steuerdaten in den USA finden Sie hier).
Allerdings gibt es immer noch mindestens zwei Probleme: Erstens haben insbesondere die Reichen, aber genauso natürlich jeder andere auch, ein eindeutiges Interesse daran, ihre Einkommen zu minimieren, um die Steuerzahlungen zu reduzieren. Zweitens verwenden die Reichen massive Programme, um ihre Besitztümer und ihr Einkommen zu verstecken, wie die Panama Papers gezeigt haben. Daher stehen wir trotz aller Bemühungen, das volle Ausmaß der Spitzeneinkommen offenzulegen, erst am Anfang eines langen Weges.
Vielleicht ist jetzt der richtige Zeitpunkt, um zu überlegen, wie die Steuerdaten verbessert, wie die Steuerdaten und die Haushaltsbefragungen vergleichbarer gemacht und – das ist am anspruchsvollsten – bessere administrative Daten (wie etwa das von Piketty und Gabriel Zucman vorgeschlagene weltweite Vermögensregister) geschaffen werden können, sowohl um Vermögen zu besteuern, als auch um Steuerhinterziehung zu bekämpfen.
Wir bewegen uns bereits auf die nächste Stufe der methodologischen Entwicklung zu, bei der die Einkommen der Reichen im Mittelpunkt stehen – weil sie so viel reicher als alle anderen geworden sind, weil sie über so viel politische Macht verfügen und weil sie ihr Vermögen verstecken.
Zum Autor:
Branko Milanovic ist Professor an der City University of New York und gilt als einer der weltweit renommiertesten Forscher auf dem Gebiet der Einkommensverteilung. Milanovic war lange Zeit leitender Ökonom in der Forschungsabteilung der Weltbank. Er ist Autor zahlreicher Bücher und von mehr als 40 Studien zum Thema Ungleichheit und Armut.
Hinweis:
Dieser Beitrag ist zuerst in Branko Milanovic´Global Inequality-Blog erschienen. Die deutsche Übersetzung erfolgte durch die Makronom-Redaktion mit Genehmigung des Autors.